Core Technologies in Dawn
This section page with high level decisions in the Dawn project. How it technically operates and explains some of the design decisions.
- Core Technologies in Dawn
- Specific Technolgies Adopted by Dawn
Choice of programming language
Java is the main programming language for Dawn developers and Python (in its C-form) is the main language for extending Dawn and interacting with data. Dawn also has support of Jython, although data analysis with Jython is not done often outside Dawn. The software developers of Dawn use Java and sometimes cpython/Jython; the scientists use cpython to analyse their data. This design was arrived at for several reasons.
The use of Java in the main product because:
1. The GDA team adopted a Java environment because of the GDA work at Daresbury. Dawn would like to be fully compatible with GDA so that online data analysis is possible. In addition Dawn provides APIs to GDA, for instance the graphing.
2. Java scales better to large software development projects compared to scripting languages like python:
a. IDEs are better, and feature rich
b. Debuggers are well developed
c. Profilers are available and easy to use
d. It is statically typed which allows powerful refactoring operations
e. There are a wide variety of APIs and a lower incidence of reinventing existing technologies compared to other technologies
3. The existing developers skilled in Java working at Diamond and other facilities
4. There is an availability of java software developers compared to languages with smaller user bases.
The use of cpython as the main scientific scripting language was chosen because:
1. There are a wide variety of scientific APIs such as numpy, scipy and matplotlib.
2. Scientists are often skilled with these areas.
3. Python is more productive for data analysis because it is shorter and easier to write scientific algorithms.
User Interface Technology (and acronym warning)
The user interface technology for Dawn is the Rich Client Platform (RCP) operating with SWT (Standard Widget Toolkit). RCP is a feature rich user interface toolkit and complete application management platform for the Java programming language. RCP sits above SWT (SWT is a user interface toolkit similar to Swing or QT) and provides the management of the application. This means that, once developers understand RCP, there is a standardized route to creating parts and actions in the user interface. This common framework means that with little work and careful design, user interface parts can be shared in different applications, GDA and Dawn for instance. IBM invested in the SWT and RCP framework originally, however now this work is in the public domain. RCP is supported on Windows, Mac and Linux so it is a good fit for the user group identified for Dawn.
OSGI
RCP is delivered using the OSGI framework. OSGI is a system for separating software products into modular plugins and managing the content provided by the plugins. It turns out to be very useful for Dawn because it means that the product can be extended to have functionality from other products. We have done with the Bioclipse and pydev products for instance. But it also means that unless the user selects to use a given piece of functionality, the only resources used for it are the disk where it is installed. This is because OSGI dynamically loads the plugins as required.
Builds
The RCP framework is provided with builders and basic installers so it is not necessary to purchase or invest in separate products for doing this part of the software delivery.
History of Products using RCP
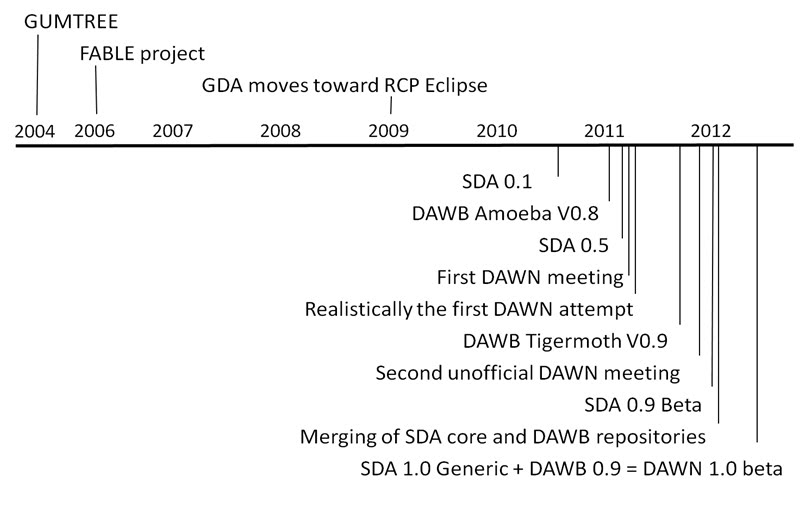 Figure 1 History of RCP Products Influencing Dawn
Figure 1 History of RCP Products Influencing Dawn
Perspectives
RCP has a feature known as perspectives which is a useful tool for us to develop custom user interfaces in Dawn. This has been used extensively to separate the product into science specific areas.
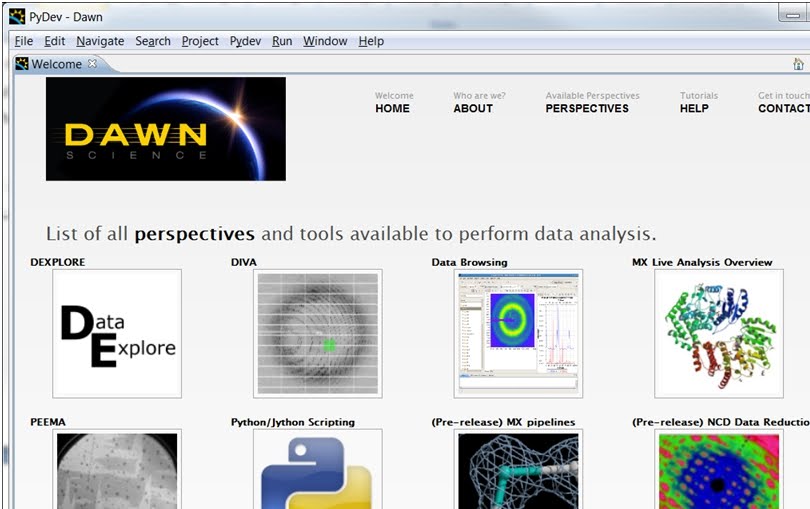 Figure 2 splitting up the user interface into science specific areas.
Figure 2 splitting up the user interface into science specific areas.
Final Choice
At the point where RCP was chosen for Dawn, GDA were moving their user interface from Swing to RCP, and SDA and DAWB already existed using RCP. So for the Dawn product Diamond Light Source and the wider collaborators decided to use RCP, influenced by the existing large amount of available features and the team of programmers experienced in it.
Source Code Control
The SDA and GDA used SVN to manage source code control. Dawn migrated from SVN in late 2011 and early 2012 to use git. A proportion of the source code is publically available on github and some proprietary features are maintained on an internal git repo (repository) but the binaries are available via the Dawn Web Site. We chose git because of the better merging capabilities and the ability to manage branches better. The expectation is that, by making version management better and easier, we will be able to deliver a better quality product in the stable branch. We have seen productivity gains with the recent Dawn 1.0 version.
Dawn Versions
Dawn normally has a two active branches, a release branch (basically a Beta program) and a master/nightly branch. There are old release branches which have only bug fixes done to them as well, but these are less active. The nightly is where volatile and more creative features can be added. A long running Beta program is good for the feature led environment in which Dawn operates. This is because there is pressure to add new features so orthogonally dependant features can be merged back to the current beta branch, providing they are judged low risk. This means that users are not exposed to more creative changes in the master/nightly branch. There was a feature freeze in Dawn 1.0 in October 2012 and a new beta program started for the next release of Dawn. Nicknames are given internally to Dawn versions, the development branch at the time of writing this page is named ‘monster’ in the Jira system.
Repositories
| Repository | Description |
|---|---|
| scisoft-ui | Scientific Software - user interface components |
| dawn-mx | MX extensions to Dawn |
| embl-cca | |
| dawn-ui | User interface plugins and features, including visualization features |
| scisoft-core | Scientific Software - core components |
| dawn-common | Common plugins |
| dawn-third | Featues and plugins for third party dependencies |
| dawn-tango | Tango features and plugins |
| dawn-workflow | Generic workflow plugins and features |
| scisoft-cbflib | Scientific Software - uk.ac.diamond.CBFlib plugins |
| dawn-isencia | Isencia model plugins |
| dawn-product | Plugins and features required for Dawn |
| dawn-isenciaui | User interface isencia |
| dawn-fable | The fable plugins used in dawn |
| dawn-test | Plugins for running test decks that are non-specific |
| dawn-edna | |
| scisoft-icat | Icat |
| scisoft-hdf | HDF5 plugins |
| dawn-examples | Example plugins, mainly used for workflows extensions |
| dawn-build | Build system projects |
Figure 4 List of repos for Dawn on GitHub
Integrated Development Environment (IDE)
Developers in scientific software contributing to Dawn are required to use an IDE for productivity reasons. We are currently using eclipse because it has better tools for RCP development and has numerous other productivity tools. Eclipse has extensions for debugging, profiling, task, source code control(git/SVN) and defect tracking (Jira) as well as core features for refactoring, code searching, code generation and code formatting.
New Developers
New developers are mentored in becoming trained with this system. The investment made in training with eclipse is returned by the productivity gains if using an IDE as part of your core job function. Scientists writing code occasionally would not necessarily benefit from this investment.
Debugging
We use pair debugging as part of our development process for checking code and getting it to run as required. Typically when a new feature is being added by a developer a colleague when required to offer help will use a pair debugging approach. This is a powerful visual way of inspecting running code and is used routinely in the scientific software team (mostly with Java code).
Pair Programming
We do not routinely use pair programming. The scientific software features are generally numerous and urgent but with a small user base with a direct connection to the developer. We have not found this environment a good fit for pair programming.
Continuous Build System
The choice of automated build system for Dawn is Jenkins. This system was already available at Diamond at the point of the Dawn product starting. It is a flexible and scalable build system and has enabled builds and automated tests of Dawn to be run continuously over the project life-cycle so far. This feature was made available by the GDA team.
Automated Tests
The automated tests are run with the build system, Jenkins and manually from our IDE eclipse. They take the following form:
1. Junit unit tests (run with the build)
2. Junit plugin tests, used for regression testing, currently only run manually.
3. Squish user interface tests
There is a technical issue running the Junit plugin tests from Jenkins which means we a currently not running these continuously. The junit and squish tests are very extensive and specific and have numerous regression tests within them so it is a requirement for them to pass before a release.
Defect (Bug) Tracking and Task Tracking
Dawn adopted the Jira system for defect tracking for the following reasons:
1. Diamond Light Source and ESRF use the Jira system.
2. Jira integrates with commonly used Java IDEs, for instance Eclipse.
3. Jira is cost effective to host.
4. It is feature rich compared to previously used technologies like trac.
5. Jira has been widely adopted by the software development community and has many extra tools available.
The 1.0 project and new feature requirements for Dawn are being managed with Jira. In addition there is an item under the help menu of Dawn called “Submit Feedback”. This allows users to submit problems or observations back into our Jira database. The Jira system is available external from Diamond Light Source for collaborators without a fedid.
There is a high level of untracked ongoing tasks required to support the beamlines at the moment. The proportion of emergency/immediate resolution tasks is high and these have not historically been logged well in Jira. Defects and development tasks have a large proportion of tracking, 90-95% and >50% respectively.
Large Design Tasks
Large development tasks are not usually planned and executed in Jira at the moment and are detailed instead on design documents. This decision was made because writing a design document can allow developers to be creative and consider all issues relating to the feature. Time and subtasks of larger features are tracked in Jira. We do not attempt accurate time prediction and waterfall management of large features. Instead we prototype early and get user feedback because our user groups are small and have specific requirements. In this sense the large designs are close to Agile methodology.
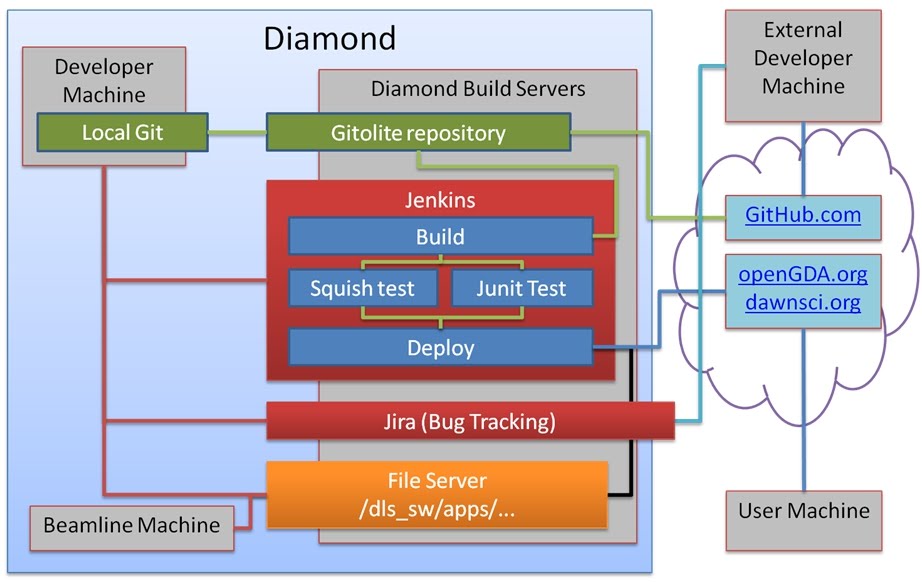
Process diagram of continuous integration and deployment for Dawn
The below figure highlights the relationships between the internal and external repositories, builds, testing and deployment servers used as part of the continuous integration and deployment system at Diamond.
Specific Technolgies Adopted by Dawn
This section deals with a selection of general features in Dawn, how/why they were added and their advantages in delivering functional high quality software for data analysis at Diamond. This is a high level view, for instance tools have extensive use in specific scientific areas and each one has an explanation within that context which is outside the scope of this document.
Datasets and file loading
Dawn loads and interacts with data in a standardized way. This means that any data format can be loaded by Dawn into a common object. The data object is loaded using a factory pattern, using a feature of RCP called extension points. This means that loaders can be plugged into Dawn to support any data format, even to a compiled and an installed product. The LoaderFactory (as we call the object which deals with this) can also be used with Spring for use with GDA. A common object, IDataset and its abstract class AbstractDataset, is used internally to the product throughout Dawn, from the maths packages, to data visualization and even workflows. This standardized approach means that tools and algorithms inside Dawn can universally interact. The API is a new build however its design is based on numpy which saved a great deal of time in developing the semantics of the API.
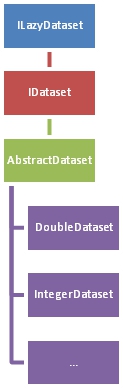
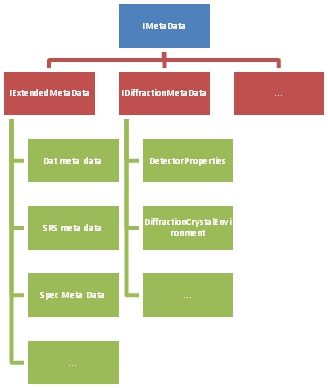
Figure 13 shows a tool in Dawn in the tools section. In this screenshot the image, the azimuthal tool and the meta data viewer are all able to interoperate because they are using the common data object.
Graphing package
Initially Diamond Light Source developed a plotting technology using hardware acceleration which dealt with 1D, 2D and 3D visualization. This was available in the SDA and GDA product at Diamond Light Source Ltd. Users were not able to use this reliably off site because in order to view 1D and 2D plots they often had to either configure a graphics card or buy one. There was a ‘software only’ version of the plotting which did not need a graphics card but this had technical issues in that it did not look the same as the graphics card plotting and did not work well over the remote desktop technology ‘NX’.
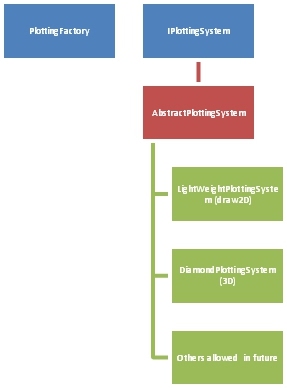
With Dawn it was decided to scrap an in house developed plotting solution for 1D and 2D and keep the existing plotting only for 3D. This means that users only have to deal with graphics card issues if they plot in 3D which is a subset of the use cases.
It was decided to use a plotting system developed externally. The plotting chosen is based on draw2D which is an API defined for plotting on web pages. Draw2D has an RCP implementation (as well as a web version) and an existing open source plotting API for 1D is available from control system studio. We adopted this API and made changes for large data and to the tick mark algorithm. For 2D we initially experimented with the 2D API available from the fable project. However this did not support the concept of regions (selections made in data such as images) therefore we decided to reuse part of fable histogramming algorithm coupled images in draw2D. This now provides all the Dawn image viewing. This design allowed the existing tools from SDA to be migrated, in addition new tools have been and continue to be developed. The Fable histogramming was made available as an eclipse service so that separation exists between the algorithm and the image implementation. For speed reasons the histogramming is currently 8-bit. We experimented with 16-bit and may move to it if a faster algorithm can be designed.
The future of 3D viewing in Dawn is likely to be javafx but currently it is JOGL.
For Dawn we decided to wrap all of the the plotting in an API (the SDA plotting used a concrete class), called ‘IPlottingSystem’. So compared to SDA, Dawn has an entirely different API to plotting. This class is abstracted from the implementation. This means that Dawn and GDA will now use the API and not the underlying implementation. This design allows swapping of the underlying graphics technology. So if we require new functionality in the future which is available off the shelf (there are a number of options for this) we can swap without changing the analysis and acquisition plotting. The plotting system is managed by a factory pattern contributed to via extension points.
HDF5
HDF5 is a file format for reading and writing large data. It allows large datasets to be dealt with almost as if they are in local memory. It has the ability to store Meta data and provide this and the data structure without loading any of the large raw data into memory. HDF5 is often used in conjunction with nexus which is an agreed standard for the storing and marking of data.
Dawn has developed two OSGI plugins for the reading and writing of HDF5/Nexus data. There are unit tests to ensure that these maintain and correctly expose the multi-threaded abilities of HDF5. The plugins are based on a high level API made available from the HDF5 consortium which gives access to HDF5 data through a tree like data structure.
Persistence
Certain tools in DAWN should be able to have their states saved in a non-volatile way and therefore use persistence. The format used enables persistence of data, regions, masks and functions from any tool to be added by the tool programmer. The persistence of data also means that one should be able to read it from the place where it was saved.
Below is the class diagram of the persistence API that gives the tool programmer the ability to save/load data, masks, regions and functions.

The resulting tree structure of an HDF5 file with saved data as defined in the API Javadoc looks like the following.
| Entry name | Class | Description |
|---|---|---|
| entry | Group | |
| entry/data | Group | |
| entry/data/image | Dataset | 64-bit floating-point |
| entry/data/xaxis | Dataset | 64-bit floating-point |
| entry/data/yaxis | Dataset | 64-bit floating-point |
| entry/mask | Group | |
| entry/mask/mask0 | Dataset | 8-bit integer |
| entry/mask/mask0/name | Attribute | String |
| entry/mask/mask1 | Dataset | 8-bit integer |
| entry/mask/mask1/name | Attribute | String |
| entry/mask/… | … | … |
| entry/region | Dataset | 8-bit integer |
| entry/region/JSON | Attribute | String |
| entry/function | Dataset | 64-bit floating-point |
| entry/function/JSON | Attribute | String |
Data, axes and masks are saved as datasets. The masks only need to be saved as boolean dataset. HDF5 format doesn’t enable the saving of boolean therefore it has to be saved using a byte dataset. As for the regions, they are serialized to a JSON string using the GSON serializer and then this string is saved as an attribute in the region node of the HDF5 file.
Data Slicing
Dawn contains a general data slicing system. This takes the form of a simple to use basic system, based on editor parts, and a more complex but complete system called DExplore, specifically the ‘Dataset Inspector’ view. You can interrogate any multi-dimensional data using either system and both work best with HDF5 data which is a format which allows lazy loading. (The nexus format is generally delivered in its HDF5 form.)
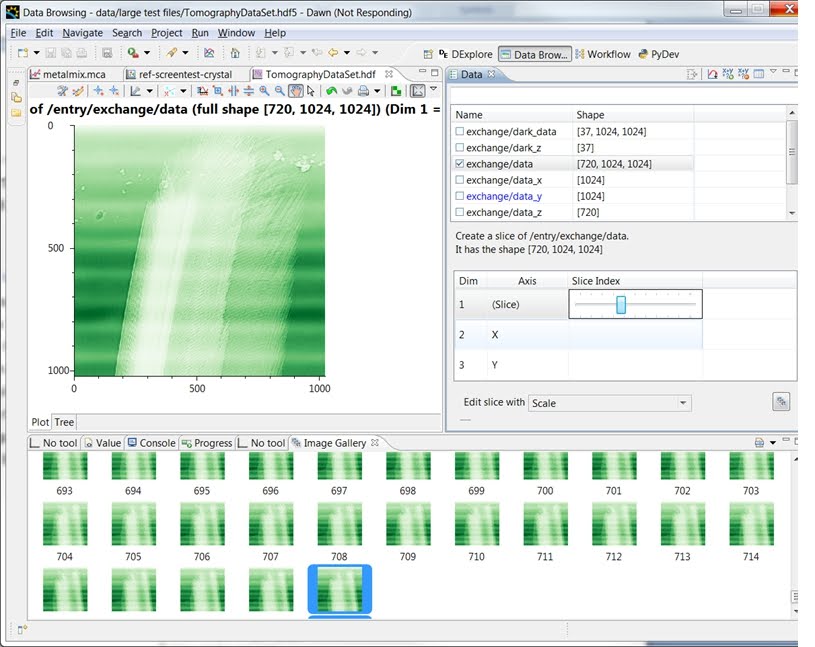
Figure 15 Easy to use data slicing in Dawn
Dawn Tool System
The tool system in Dawn is based on the mathematics of the SDA tool system (which was known as ‘side plot’) and the eclipse page system, which is a system which donates content to a view based on selection context (i.e. which file/data the user is looking at). This approach allows the user interface to appear simpler to the user compared to making all tools available all the time. If, for instance, the user is interested in an azimuthal profile of an image they will not see unrelated tools (such as peak fitting for instance) unless they make a specific choice to use them. This system also attempts to close components which have not been specifically chosen to remain open when the user switches to the new tool.
Python Interface
Dawn has python support for data analysis. Rather than create python editors, python command line and debugger, we have been able to use an existing implementation available in RCP called pydev. This has been customised for running data analysis python and is a key component of Dawn. Dawn can communicate with cpython meaning for instance that numpy and Dawn plotting can be combined, so images can be visualized after mathematical operations. Dawn provides a library called scisoftpy as the interface between Dawn features and python data analysis.
The python functionality, ability to connect between cpython and Java and extensions to pydev were completed by a contractor. A link to the report from this development to Dawn has been added in the appendices.
Workflows
Dawn contains a feature known as workflows. These have not been developed but customized from an open source product known as Passerelle (which has Swing and RCP versions) and another RCP product developed by the ESRF called DAWB. Workflows allow algorithms to be designed and visualized with a diagram (in this case for data analysis) and executed and modified on the fly, without programming knowledge. For instance it is possible to create parallel programs without programming threads because the threading is managed by the workflow engine. This feature is Beta quality in Dawn 1.0 and probably the release afterwards because there are a number of parts of the functionality which are currently difficult to use. The user interface is not reliable and feature rich enough for an ordinary user to easily pick up workflows. Developers working on Dawn have a good relationship with the commercial company behind Passerelle and it is hoped that some of the user friendly issues will be solved in 2013.
A paper published by scientists at the ESRF (collaborators on the Dawn product) details one usage of workflows for aligning a kappa goniometer.
http://journals.iucr.org/d/issues/2012/08/00/gm5021/gm5021.pdf
ICAT connection
The ICAT project holds data for synchrotron and neutron experiments and provides a web service for navigating the data, viewing meta-data and downloading the data. The ICAT functionality in Dawn connects to the web service (SOAP) using JAX-WS. This provides a remote API to the service. This is used inside the eclipse architecture to create a tree of visit data. This can browse the data and view meta-data. When the user double clicks on a file it is downloaded using the sftp and they can view it in a standard Dawn image viewing part.
Tutorials
The Dawn software has available a tutorial system. The aim is that each piece of functionality has a tutorial for training a would-be user in how to use it. This is available under the Help menu and labelled ‘Cheat sheets and Tutorials’. The feature is already available in the RCP platform so the developers of Dawn features contributed the content for their tutorials in xml format rather than creating a new system.
Graphical Processing Unit (GPU) connection
Dawn provides connection to opencl enabled graphics cards for GPU processing, via an eclipse plugin driving an open source product known as aparapi. This enables java to be written in a simple way though a JNI connection driving the graphics processing unit. We have not made the final decision to use cuda or opencl for GPU connections as yet and may provide plugins for driving both in future, especially if the APIs are made as easily available as aparapi.